IBM has introduced new set of commands to easily repair the damaged data on the directory-container storage pool on both source and target TSM servers when you enable replication techniques. By using these commands you can save lots of time and money which we spend on recovering the damaged storage pools earlier. You can use PROTECT STGPOOL, AUDIT CONTAINER and REPAIR STGPOOL commands to repair the damaged data on the directory-container storage pool on both source and target TSM servers.
Infact, the repairing process of the directory-container storage pool on the target server is done automatically by using the above commands. In this post we will see the steps to repair damaged data on the directory-container storage pool on a source server.
Steps to follow to repair damaged data on the directory-container storage pool on a source server
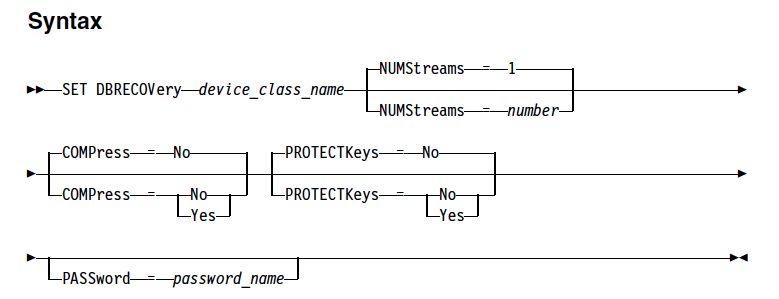
Step1: Enable protection manually or automatically
You can protect the storagepools by configuring automatic protection or manual protection.
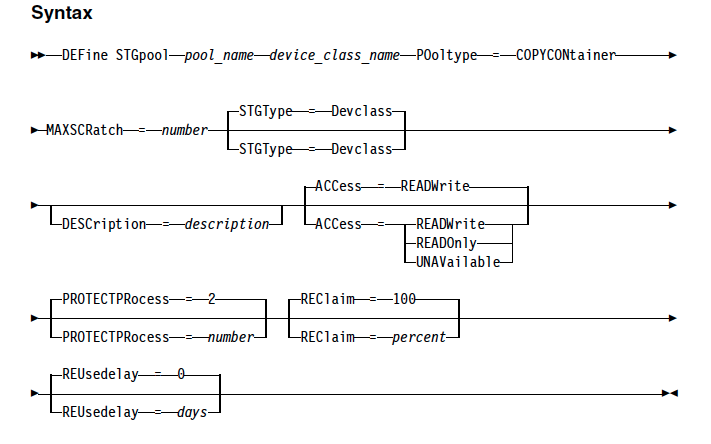
To enable storagepool protection automatically, specify the PROTECTSTGPOOL parameter on the DEFINE STGPOOL or UPDATE STGPOOL command to back up the data. For example
update stgpool prodpool protectstgpool=proddrpool
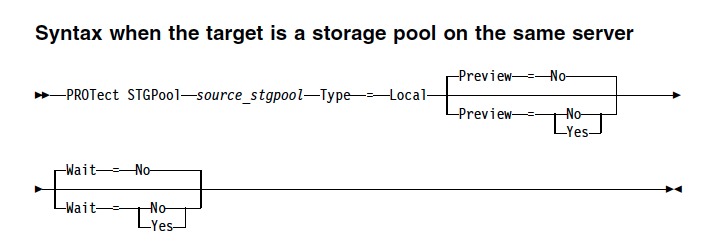
To enable storagepool protection manually, use PROTECT STGPOOL command to protect data in directory-container storage pools by storing the data in another directory-container storage pool on the target server. When you issue this command, data that is stored in the directory-container storage pool on the source server is backed up to a directory-container storage pool on the target server. You should issue this command on the server that is the source server for data.

protect stgpool devpool maxsessions=5
Use the FORCEREConcile parameter to specify whether to reconcile the differences between data extents in the directory-container storage pool on the source server and target server. If you specify NO to this option, the data backup does not compare all data extents in the directory-container storage pool on the source server with data extents on the target server. Instead, data backup tracks changes to the data extents on the source server since the last backup and synchronizes these changes on the target server. If you specify YES, the data backup compares all data extents on the source server with data extents on the target server and synchronizes the data extents on the target server with the source server.
Step 2: Repair the storagepool by using REPAIR STGPOOL command
By protecting the directory-container storage pool, you can repair damaged storage pools by using the REPAIR STGPOOL command. It is used to repair deduplicated extents in a directory-container storage pool. Damaged deduplicated extents are repaired with extents that are backed up to the target server.

repair stgpool devpool maxsessions=5
You must issue the PROTECT STGPOOL command to back up data extents to the directory-container storage pool on the target server before you issue the REPAIR STGPOOL command. The REPAIR STGPOOL command fails when any of the following conditions occur:
- The target server is unavailable.
- The target storage pool is damaged.
- A network outage occurs.