Solid State Drives (SSDs) are storage devices that contain non-volatile flash memory. Solid state drives are superior to mechanical hard disk drives (HDD) in terms of performance, power use, and availability. These drives are especially well suited for low-latency applications that require consistent, low (less than 1 ms) read/write response times.
SSDs consume less power compared to hard disk drives. Because SSDs do not have moving parts, they generate less heat compared to HDDs. Therefore, it further reduces the need for cooling in storage enclosure, which further reduces the overall system power consumption.
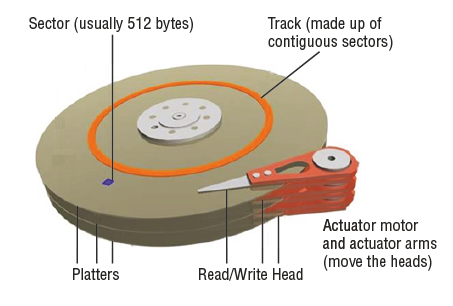
Physical Solid State Drive (SDD) Structure
In a HDD servicing, small-block, highly-concurrent, random workloads involve considerable rotational and seek latency, which significantly reduces throughput. Externally solid state drives have the same physical format and connectors as mechanical hard disk drives. This maintains the compatibility in form and format with mechanical hard disk drives, and allows easy replacement of a mechanical drive with a solid state drive. Internally, a solid state drive’s hardware architecture consists of the following components: I/O interface, controller, and mass storage.
 Components")
I/O interface: The I/O interface enables connecting the power and data connectors to the solid state drives. SSDs typically support standard connectors such as SATA, SAS, or FC.
Controller: The controller includes a drive controller, RAM, and non-volatile memory (NVRAM). The drive controller manages all drive functions. The SSDs include many features such as encryption and write coalescing. The non-volatile RAM (NVRAM) is used to store the SSD’s operational software and data. Not all SSDs have separate NVRAM. Some models store their programs and data to the drive’s mass storage. The RAM is used in the management of data being read and written from the SSD as a cache, and for the SSD’s operational programs and data. The portion of the drive’s RAM used for controller cache enhances the overall performance of the SSD. Mass storage, which is made of flash memories, writes slower than it reads. The drive’s RAM is used to minimize the number of writes to mass storage and improve the response time of the drive.
Mass Storage (Flash Memory): The mass storage is an array of non-volatile memory chips. They retain their contents when powered off. These chips are commonly called Flash memory. The number and capacity of the individual chips vary directly in relationship to the SSD’s capacity. The larger the capacity of the SSD, the larger is the capacity and the greater is the number of the Flash memory chips.
The Flash memory chips that make up the drive’s mass storage come from numerous manufacturers. Two types of Flash memory chip are used in commercially available SSDs: Single-Level Cell (SLC) and Multi-Level Cell (MLC). SLC-type Flash is typically used in enterprise-rated SSDs for its increased memory speed and longevity. MLC is slower but has the advantage of greater capacity per chip. Although SLC type Flash memory offers a lower density, it also provides a higher level of performance in the form of faster reads and writes. In addition, SLC Flash memory has higher reliability. As SLC Flash memory stores only one bit per cell, the likelihood for error is reduced. SLC also allows for higher write/erase cycle endurance. For these reasons, SLC Flash memory is preferred for use in applications requiring higher reliability, and increased endurance and viability in multi-year product life cycles.
Solid State Drive (SSD) Addressing
Solid state memory chips have different capacities, for example a solid state memory chip can be 32 GB or 4 GB per chip. However, all memory chips share the same logical organization, that is pages and blocks.
At the lowest level, a solid state drive stores bits. Eight bits make up a byte, and while on the typical mechanical hard drive 512 bytes would make up a sector, solid state drives do not have sectors. Solid state drives have a similar physical data object called a page. Like a mechanical hard drive sector, the page is the smallest object that can be read or written on a solid state drive. Unlike mechanical hard drives, pages do not have a standard capacity. A page’s capacity depends on the architecture of the solid state memory chip. Typical page capacities are 4 KB, 8 KB, and 16 KB.
Page and Block Concepts in SSD
PAGE: A page has three possible states, erased (empty), valid, and invalid. In order to write any data to a page, its owning block location on the flash memory chip must be electrically erased. This function is performed by the SSD’s hardware. Once a page has been erased, new data can be written to it. For example, when a 4 KB of data is written to a 4 KB capacity page, the state of that page is changed to valid, as it is holding valid data. A valid page’s data can be read any number of times. If the drive receives a write request to the valid page, the page is marked invalid and that write goes to another page. This is because erasing blocks is time consuming and may increase the response time. Once a page is marked invalid, its data can no longer be read. An invalid page needs to be erased before it can once again be written with new data. Garbage collection handles this process. Garage collection is the process of providing new erased blocks.
BLOCK: A block has three possible states, erased (empty), new, and used. Once a block is erased, a block’s number of pages that have been assembled in the SSD’s RAM may be written to it. For example, thirty two 4 KB pages may be assembled into a block, and then written to the erased block. This sets the block’s state to “new”, meaning it is holding pages with valid data. A block’s valid pages can be read any number of times. There are two mechanisms to invalidate a page, writes and deletes. If the drive receives a write request to a valid block page, the page must be changed. The current page containing the destination of the write is marked invalid. The block’s state changes to “used”, because it contains invalid pages. These writes go to another page, on an erased block. A delete invalidates a page without resulting in a subsequent write.
Performance of an Solid State Drive (SSD)
SSD performance is dependent on access type, drive state, and workload duration. SSD performs random reads the best. In carefully tuned multi-threaded, small-block random I/O workload storage environments, SSDs can deliver much lower response times and higher throughput than HDDs. This is because random-read I/Os cannot usually be serviced by read-ahead algorithms on a HDD or by read cache on the storage system.
The latency of a random read operation is directly related to the seek time of a HDD. For HDDs, this is the physical movement of the drive’s read/write head to access the desired area. Because they are random access devices, SSDs pay no penalty for retrieving I/O that is stored in more than one area; as a result their response time is in an order of magnitude faster than the response time of HDDs.
For large block I/Os, SSDs tend to use all internal I/O channels in parallel. Since the single-threaded sequential I/O streams on FC HDDs do not suffer seek and rotational latencies because of the storage system cache, single-threaded large-block sequential I/O streams will not show major performance improvements with SSDs over FC HDDs.
However, with the increased application concurrency (as more threads are added), the load starts to resemble a large block-random workload. In this case, seek and rotational latencies are introduced that decrease the FC HDD effectiveness but do not decrease SSD effectiveness.
A new SSD or an SSD with substantial unused capacity has the best performance. Drives with substantial amounts of their capacity consumed will take longer to complete the read-modify-write cycle. SSDs are best for workloads with short bursts of activity.
Previous: 2.2 ElectroMechanical Hard Disk Drive (HDD) Overview
Next:
Previous: 2.2 ElectroMechanical Hard Disk Drive (HDD) Overview
Next:
 Components")









 categories")